Rust and dynamically-sized thin pointers

One of Rust's notable differences from C is its requirement that all values have a defined size, which enables runtime bounds-checking and advanced static analysis tooling such as MIRI. For dynamically-sized types (DSTs) this requirement is implemented using thick pointers, such that each pointer to a dynamically-sized value is an (address, size) tuple.
Thick pointers are more convenient and easier to use correctly than the C idiom of passing around value sizes manually, but they have a performance drawback – each thick pointer takes up twice as many registers as a thin pointer, even when pointing to values for which the size can be trivially computed. This overhead is especially noticeable for code that processes packet-based network protocols, which can cause Rust code to underperform C in that niche.
vu128: Efficient variable-length integers

LEB128 is a simple self-synchronizing encoding for variable-length integers. Although widely used, its 30-year-old bitstream format is inefficient on modern hardware. Packing the integer's width into a prefix byte works just as well for machine-sized integers, and is much faster.
Creating TUN/TAP interfaces in Linux

TUN/TAP is a widely implemented API for userspace networking on UNIX platforms. This page contains a worked example of creating a TUN/TAP network interface in Linux, including interface configuration with Netlink.
Running SunOS 4 in QEMU (SPARC)

SunOS is a historical UNIX operating system widely used from the mid 80s into the early/mid 90s. Older versions of QEMU struggled to emulate the SPARC platform that SunOS ran on, but QEMU v7.2 supports SPARC well enough to install and run SunOS without any unusual workarounds.
Improved UNIX socket networking in QEMU 7.2

QEMU 7.2 quietly introduced two new network backends, -netdev dgram and -netdev stream. Unlike the older -netdev socket, these new backends directly support AF_UNIX socket addresses without the need for an intermediate wrapper tool.
Debugging Win32 binaries in Ghidra via Wine
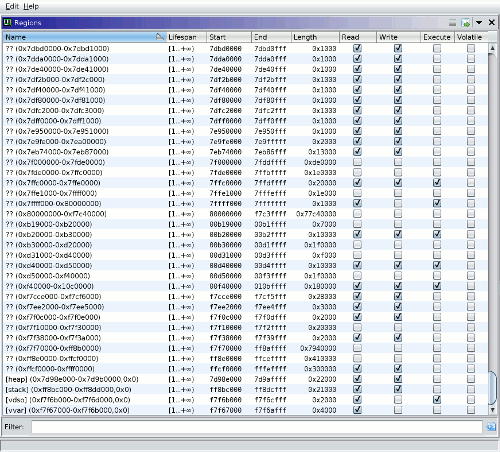
Ghidra is a cross-platform reverse-engineering and binary analysis tool, with recent versions including support for dynamic analysis. I want to try using it as a replacement for IDA Pro in reverse-engineering of Win32 binaries, but hit bugs related to address space detection when running gdbserver with Wine (ghidra#4534).
This post contains custom GDB commands that allow Ghidra to query the Linux process ID and memory maps of a Win32 target process running in 32-bit Wine on a 64-bit Linux host.
Running BeOS 5 in QEMU (i386)
BeOS is an operating system from the '90s, notable for its prescient technical decisions and abject business failure. It embraced multi-threading at a time when 100mhz CPUs powered top-shelf workstations, and featured metadata-backed virtual folders ten years before their arrival in mainstream OSes.
Gmail accepts forged YouTube emails
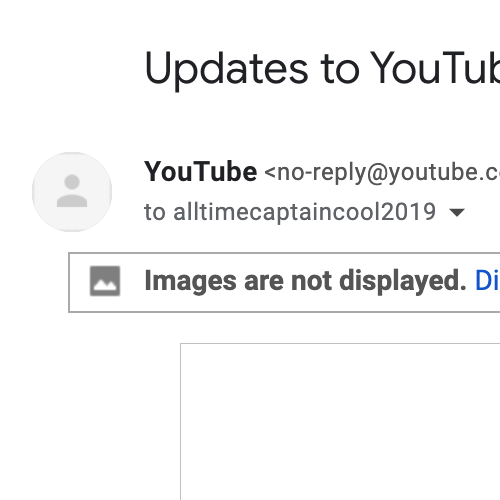
This morning I woke up to an official-looking email from YouTube in my inbox, addressed to an address that isn't mine. Long ago this sort of thing would happen if someone sent an email with forged headers (e.g. to fish for logins), but the advent of DKIM and DMARC has relegated header forging to ancient history. I was greatly surprised to see that the forged email had passed Gmail's DKIM/DMARC checks.
Compacting Lunr search indices

Lunr is a small JavaScript library for full-text search, which I recently used to implement client-side search for this site. The user experience of client-side search depends in part on how large the search index is, and Lunr's default JSON encoding is more verbose than it needs to be. This page describes a more compact encoding that can reduce the serialized index size by about 40%.
JSON is not a YAML subset
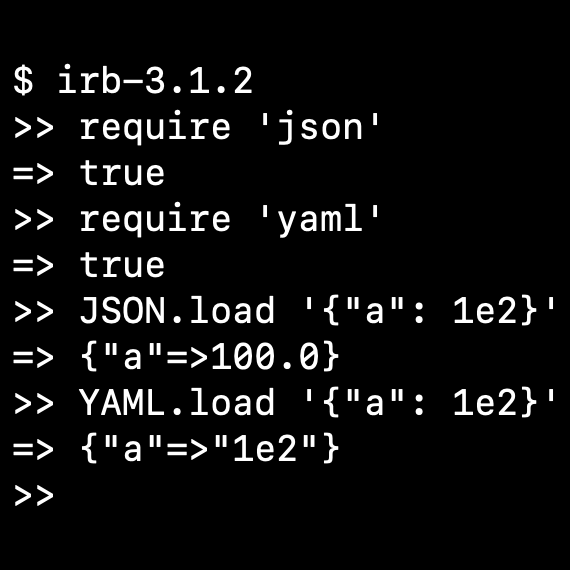
Don't try to parse JSON with a YAML parser. Stop telling other people to parse JSON with a YAML parser.
Stateless Kubernetes overlay networks with IPv6

The Kubernetes network model is typically implemented by an overlay network, which allows pods to have an IP address decoupled from the underlying fabric. IPv4 overlay networks have a number of well-documented drawbacks, which contributes to Kubernetes' reputation as difficult to operate beyond small cluster sizes (~10,000 machines).
This page describes an overlay network based on stateless IPv6 tunnels, which have better reliability and scalability characteristics. It uses IETF protocols that are natively supported by the Linux kernel, and since it is independent of Kubernetes itself can support communcication between processes both inside and outside of containers.
Extending VSCode with WebAssembly
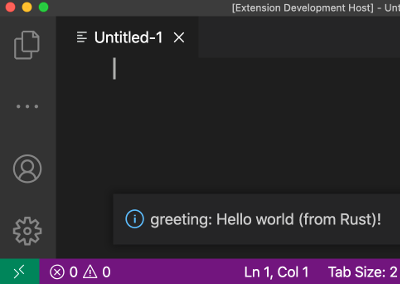
Two years ago I filed Microsoft/vscode#65559 asking for WebAssembly support in VSCode extensions. At the time, WASM was supported by Node.JS but the WebAssembly symbol wasn't available in the extension's evaluation scope. That issue didn't get much activity from upstream but the other day I tried it again, and … it worked!
Notes on cross-compiling Rust

How to get working cross-compilation from macOS to ARMv7 Linux with either Cargo or Bazel, plus some suggestions for the rustup and rules_rust projects that could make cross-compilation simpler in the future.
First impressions of Rust

Notes on finishing my first large Rust project, a FUSE server implementation. Overall I quite like Rust the language, have mixed feelings about the quality of ancillary tooling, and have strong objections to some decisions made by the packaging system (Cargo + crates.io).
SRE School: No Haunted Forests

You've heard the euphemism tech debt, where like a car loan you hold a recurring obligation in exchange for immediate liquidity. But this is misleading: bad code is not merely overhead, it also reduces optionality for all teams that come in contact with it. Imagine being unable to get indoor plumbing because your neighbor has a mortgage!
Thus a better analogy for bad code is a haunted forest. Bad code negatively affects everything around it, so engineers will write ad-hoc scripts and shims to protect themselves from direct contact with the bad code. After the authors move to other projects, their hard work will join the forest.
Error Beneath the WAVs
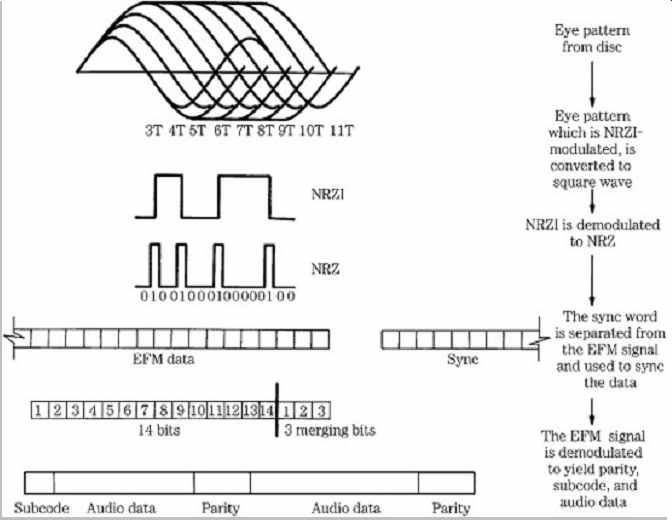
This is a follow-up to Why I Ripped The Same CD 300 Times. By the end of that page I'd identified a fragment of audio data that could cause read errors even if it was isolated and burned to a fresh CD. This page explores how specific bit patterns named weak sectors can create corrupt physical media by tickling bad encoding logic in a CD burner.
I also explore dusty archives of the early 2000s game piracy scene, which was very concerned about mitigating weak sectors used as copy protection. With the power of a “two-sheep” LTR-40125S drive, I successfully ripped the original discs with bit-exact audio data and a matching AccurateRip report.
Why I Ripped The Same CD 300 Times

I collect music by buying physical CDs, digitizing them with Exact Audio Copy, and scanning the artwork. This is sometimes challenging if the CD was self-published in a limited run in a foreign country ten years ago. It is very challenging if the CDs have an innate defect that renders some tracks unreadable.
“Plumbing the depths of obsession” – Jeff Atwood
Also see the follow-up post Error Beneath the WAVs for more investigation about what exactly is wrong with my discs, and info about which CD drives are capable of reading them.