Mojibake in Surugaya Javascript
Yesterday I bought some used CDs from the online store Surugaya. The checkout process was broken in an interesting way: when I clicked the payment method confirmation button, nothing happened. I switched from Chrome to Firefox and was able to place an order successfully

The bug
A quick look in the web console showed some errors in loading the page's required Javascript:
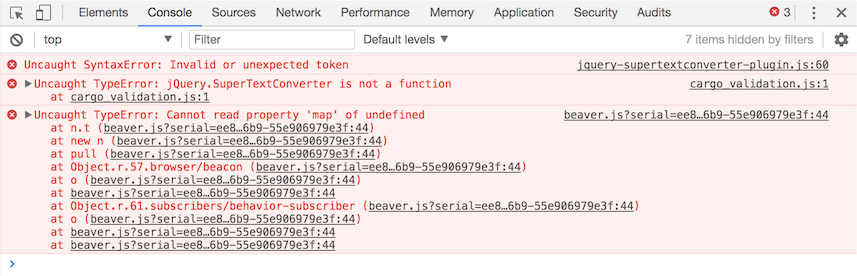
Indeed, line 60 of the script was obviously invalid:
/*! jQuery Super Text Converter 2014-03-03
* Vertion : 1.0.3
* Dependencies : jQuery *
* Author : MegazalRock (Otto Kamiya)
* Copyright (c) 2014 MegazalRock (Otto Kamiya);
* License : */
[...]
58 },{
59 zenkaku : /¥/g,
60 hankaku : '\'
61 },{
Root cause analysis
How did this happen? There are two important clues:
- First, Japanese editions of Windows use the Yen sign to render U+005C, instead of the backslash. This is backwards-compatibility behavior from pre-Unicode days when all characters needed to fit in a single byte – the JIS X 0201 character set used 0x5C for the Yen sign, and so Japanese editions of DOS use ¥ for the directory separator. Even after Windows gained Unicode support, it still renders ¥ instead of \ when running in a Japanese locale.
- Second, if the Surugaya version is compared with jquery-supertextconverter-plugin.js v1.0.3 we see two changes that look intentional, and several that look erroneous:
--- https://github.com/megazalrock/jquery-supertextconverter/blob/1.0.3/dist/jquery-supertextconverter-plugin.js
+++ https://www.suruga-ya.jp/js/jquery-supertextconverter-plugin.js
@@ -21,7 +21,7 @@
hyphen: true
},
zenkakuHyphen: 'ー',
- zenkakuChilda: '〜'
+ zenkakuChilda: '縲鰀'
}, options);
stc.regexp = {
hankaku : /[A-Za-z0-9#$%&\\()*+,.\/<>\[\]{}=@;:_\^`]/g,
@@ -57,16 +57,16 @@
type: 'space'
},{
zenkaku : /¥/g,
- hankaku : '¥'
+ hankaku : '\'
},{
- zenkaku : /[ー―‐−]/g,
+ zenkaku : /[ー―‐竏綻/g,
hankaku : '-',
type : 'hyphen'
},{
zenkaku : /|/g,
hankaku : '|'
},{
- zenkaku : /[~〜]/g,
+ zenkaku : /[~縲彎/g,
hankaku : '~',
type: 'tilda'
},{
@@ -99,7 +99,7 @@
zenkaku : ' ',
type: 'space'
},{
- hankaku : /[¥\\]/g,
+ hankaku : /[\\\]/g,
zenkaku : '¥'
},{
hankaku : /[\-ー]/g,
@@ -140,7 +140,7 @@
/ラ/g, /リ/g, /ル/g, /レ/g, /ロ/g,
/ワ/g, /ヲ/g, /ン/g,
/ァ/g, /ィ/g, /ゥ/g, /ェ/g, /ォ/g,
- /ャ/g, /ュ/g, /ョ/g,
+ /ャ/g, /ュ/g, /ョ/g, /ッ/g,
/゙/g, /゚/g, /。/g, /、/g
];
this.zenkakuKanaList = [
@@ -160,7 +160,7 @@
'ラ', 'リ', 'ル', 'レ', 'ロ',
'ワ', 'ヲ', 'ン',
'ァ', 'ィ', 'ゥ', 'ェ', 'ォ',
- 'ャ', 'ュ', 'ョ',
+ 'ャ', 'ュ', 'ョ', 'ッ',
'゛', '゜', '。', '、'
];
};
This is a case of mojibake!
Mojibake (文字化け) (IPA: [mod͡ʑibake]; lit. "character transformation", from the Japanese 文字 (moji) "character" + 化け (bake, pronounced "bah-keh") "transform") is the garbled text that is the result of text being decoded using an unintended character encoding. The result is a systematic replacement of symbols with completely unrelated ones, often from a different writing system.
What I think happened is someone wanted to add 「ッ」 to the replacement lists at the end, so they edited the source file with some basic text editor. The editor was running in a Japanese locale and interpreted the UTF-8 source as some other encoding, causing mojibake. When the new file was saved, the corruption was preserved.
Identifying the mystery encoding
Which encoding did the editor use? A web search for 「¥」 will obviously not find anything useful, so lets use one of the other replacements. https://www.google.com/search?q="縲鰀" has some relevant results:
- 「縲鰀」とはどういう意味ですか? ("What is the meaning of 「縲鰀」?")
- 縲鰀の謎 ("The mystery of 縲鰀")
These confirm other people have encountered this exact error before, but neither says which encoding is involved.
Note something interesting – two of the bad replacements consumed a trailing ]. The unknown encoding must be variable-width.
We can construct a table of likely candidates:
| Character | Unicode | UTF-8 | Shift JIS | EUC-JP |
|---|---|---|---|---|
' | U+0027 | x27 | x27 | x27 |
] | U+005D | x5D | x5D | x5D |
− | U+2212 | xE2 x88 x92 | x81 x7C | xA1 xDD |
〜 | U+301C | xE3 x80 x9C | x81 x60 | xA1 xC1 |
彎 | U+5F4E | xE5 xBD x8E | x9C x5D | xD7 xBE |
竏 | U+7ACF | xE7 xAB x8F | xE2 x88 | xE3 xE8 |
綻 | U+7DBB | xE7 xB6 xBB | x92 x5D | xC3 xBE |
縲 | U+7E32 | xE7 xB8 xB2 | xE3 x80 | xE5 xE0 |
鰀 | U+9C00 | xE9 xB0 x80 | xEF xCD | x8F xEB xA5 |
That did it! We can see how some of the bytes match up:
0x5Dshows up at the end of the Shift JIS encodings0x9Cis at the end ofutf8("〜")and the start ofshift_jis("彎")utf("〜")starts with0xE3 0x80, which isshift_jis("縲").
This file was encoded in UTF-8, but edited as Shift JIS. We can test this theory using Python:
$ python
>>> print u"〜]".encode("utf8").decode("shift_jisx0213")
縲彎
>>> print u"−]".encode("utf8").decode("shift_jisx0213")
竏綻
>>> print u"〜".encode("utf8").decode("shift_jisx0213")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'shift_jisx0213' codec can't decode byte 0x9c in position 2: incomplete multibyte sequence
Close, but not quite. Something else is going on. shift_jis('縲鰀') is 0xE3 0x80 0xEF 0xCD, and 0xEF doesn't show up anywhere else in the table. What if the editor was being really clever, and restarting the encoding autodetector each time it fails to decode a multi-byte sequence?
>>> bytes = u"〜".encode('utf8')
>>> bytes += '\x00' # padding
>>> print bytes[0:2].decode('shift_jisx0213') + bytes[2:4].decode('utf-16-be')
縲鰀
There it is. The unknown editor thought the best way to load a UTF-8 file was to parse it as a mix of Shift JIS and big-endian UTF-16.
Impact timeline
How long has this online store been serving up invalid, payment-breaking Javascript on its checkout page?
$ curl -v -o /dev/null https://www.suruga-ya.jp/js/jquery-supertextconverter-plugin.js 2>&1 | grep -E 'Date:|Last-Modified:' < Date: Sat, 24 Mar 2018 07:46:01 GMT < Last-Modified: Wed, 20 Jan 2016 07:38:19 GMT
Over two years. Hmmm.
Reporting to the webmaster
Surugaya does not have a published email address, and their order confirmation mail helpfully notes that replies are not monitored. Their contact form is at https://www.suruga-ya.jp/toiawase. Since they're located in Japan and have no English text on their site, I figured mangled Japanglish would be more successful than English. Here's the best I could do with Google Translate and a dictionary:
こんにちは、
「支払方法の選択」のページにjavascriptのエラーがありますから、Chromeの使いの顧客は購買できません。
エラーの写真: https://i.imgur.com/N9d0J08.png
このファイル: https://www.suruga-ya.jp/js/jquery-supertextconverter-plugin.js
},{
zenkaku : /¥/g,
hankaku : '\' <- これは悪い
},{
元のファイルは正しいかもしれないと思います。
https://github.com/megazalrock/jquery-supertextconverter/blob/master/src/superTextConverter.js#L60-L63
},{
zenkaku : /¥/g,
hankaku : '¥' <- これは良い
},{
僕の変な日本語はごめんあさい。返事なら、日本語も英語もいいです。
Their contact form has a "reset" button right next to the submit button, and the message field gets cleared on navigate-back, so I got to type that up twice. いい練習ですね。
When I click the submit button, nothing happens. I switch to Firefox again and am able to submit their contact form.
The second bug
The contact form directs to a confirmation page, which notes that I'm about to submit an empty message. What?
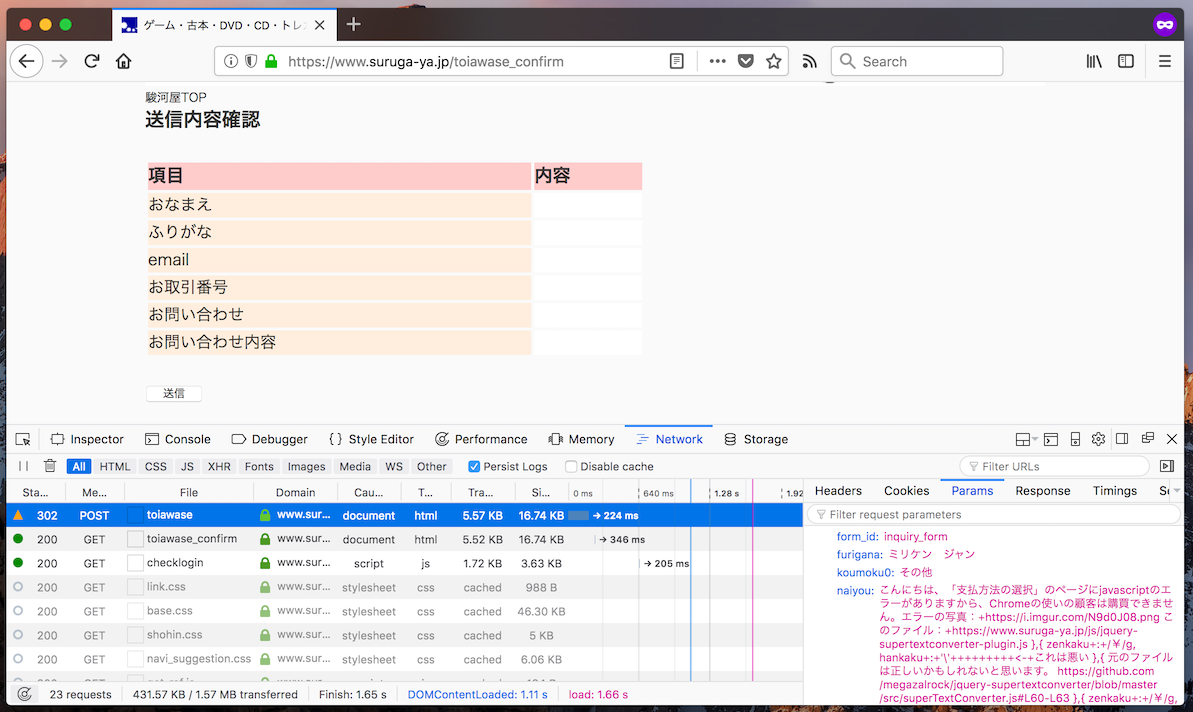
I can see the POST values got sent over correctly, but the confirmation page thinks I tried to submit an empty message. It's not just a rendering problem either, the "confirm" button there just serves up a error about the missing fields. Whatever's happening seems to be server-side, and I have no visibility into it.
Another attempt at contact
Looking at the source for the page, I notice it has <link rev="made" href="mailto:info@act-system.com"> in it. Maybe this "act system" is a web development firm responsible for the shop, and they will be able to fix the script?
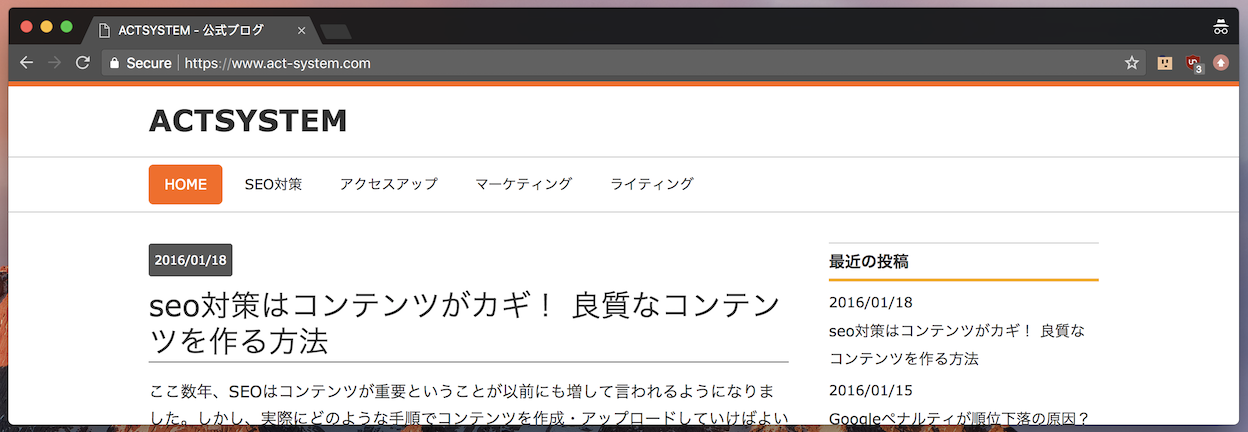
Looks like an SEO company rather than a web developer, and the last activity is from January 2016. Probably coincidental that their final blog post was written two days before the Last-Modified date on that broken script.
What did we learn, Palmer?
Text encoding is still hard.
After making changes to your website, consider diffing to make sure the delta is what you expected.
If you're going to ignore email in favor of a contact form, consider testing your contact form.
If your online store's sales funnel drops all users of the #1 most popular browser, you may be leaving money on the table from potential customers who don't know how to debug your Javascript.
Via PayPal, obviously. I'm not about to type my credit card number into a site that behaves like this.
Shift JIS unified JIS X 0201 and JIS X 0208 into a single character set.