Why I Ripped The Same CD 300 Times
I collect music by buying physical CDs, digitizing them with Exact Audio Copy, and scanning the artwork. This is sometimes challenging if the CD was self-published in a limited run in a foreign country ten years ago. It is very challenging if the CDs have an innate defect that renders some tracks unreadable.
(Русский перевод: Зачем я рипнул один компакт-диск 300 раз)
UPDATE (2018-08-10): See the follow-up post Error Beneath the WAVs for more info about what exactly is wrong with my discs, and info about which CD drives are capable of reading them. I got a perfect rip by upgrading to a "two-sheep" CD drive.
帰るべき城

The piano arrangement album 帰るべき城 by Altneuland was published in 2005. I discovered it in 2008 (probably on YouTube), downloaded the best copy I could find, and filed it away in the TODO list. Recent advances in international parcel forwarding technology let me buy a used copy last year, but when it arrived none of my CD drives could read track #3. This sort of thing is common when buying used CDs, especially if they need to transit a USPS international shipping center. I shelved it and kept on the lookout for another copy, which I located last month. It arrived on Friday, I immediately tried to rip it, and hit the exact same error. This didn't seem to be an issue of wear or damage – the CD itself was probably defective from the factory.
I had three choices: accept an imperfect rip in my archives
How Ripping Works
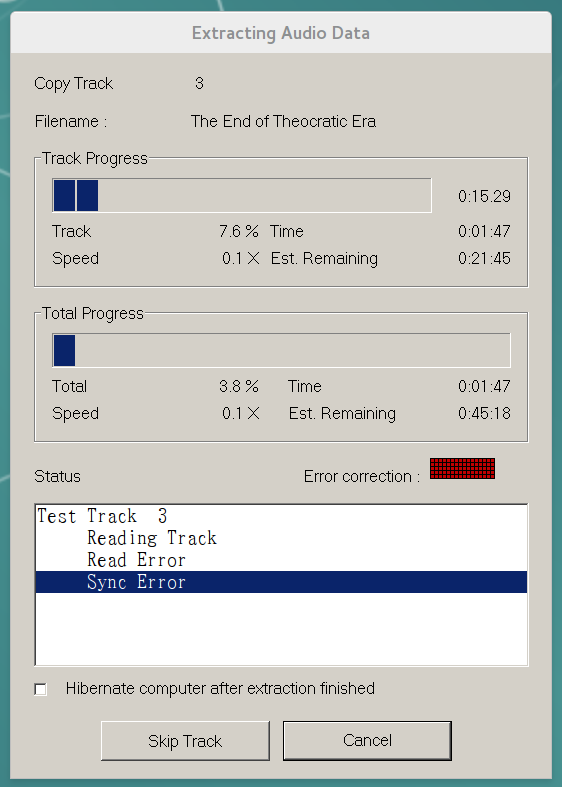
EAC failing to read track #3 of 「帰るべき城」
CDs store digital data, but the interface between CDs, lasers, and optical diodes is very analog. Read errors can be caused by anything from dirty media, to scratches on the protective polycarbonate layer, to vibration from the optical drive itself. The primitive error correction codes in the CDDA standard, designed to minimize audible distortions on lightly used disks, are not capable of fully recovering the bitstream on CDs with a significant error rate. Contemporary CD ripping software works around this with two important error detection techniques: redundant reads and AccurateRip.
The page EAC: Extraction Technology describes EAC's approach to redundant reads:
In secure mode this program either reads every audio sector at least twice [...] If an error occurs (read or sync error), the program keeps on reading this sector, until eight of 16 retries are identical, but at maximum one, three or five times (according to the selected error recovery quality) these 16 retries are read. So, in the worst case, bad sectors are read up to 82 times!
Simple enough. If a read request sometimes returns bad data, read everything twice, and then be extra careful if the first two reads didn't match. AccurateRip is the same principle, but distributed – it's a service to which rippers can submit checksums of their ripped audio files. The idea is that if you rip a track and see that a thousand other people got the same bits for the same track, then your rip was probably good.
This article is about what happens with both techniques fail. EAC can't make progress if every single read returns different data, and because it's rare the AccurateRip database only had a single entry
“I walked ten thousand aisles, ten thousand aisles to see you”

Optical drives from Asus, LG, Lite-On, Pioneer, and an unknown OEM
A practical solution to CDs that won't rip is to use a different drive. Sometimes a particular model is especially lenient with the CDDA spec or has better error correction firmware or whatever. The DBpoweramp forums maintain a CD/DVD Drive Accuracy List for rippers to select a good drive.
On Saturday morning I bought five new CD drives from different brands
But now I had a .wav file sitting on disk, and a way to get more of them. Reasoning that the read errors on a bad disk will fluctuate around the "correct" value, I figured I'd rip it a couple times, find the most "voted" value for unstable bytes, and use that as a correction. This approach was ultimately successful, but was far more work than I expected.
“Quantity has a quality all its own”
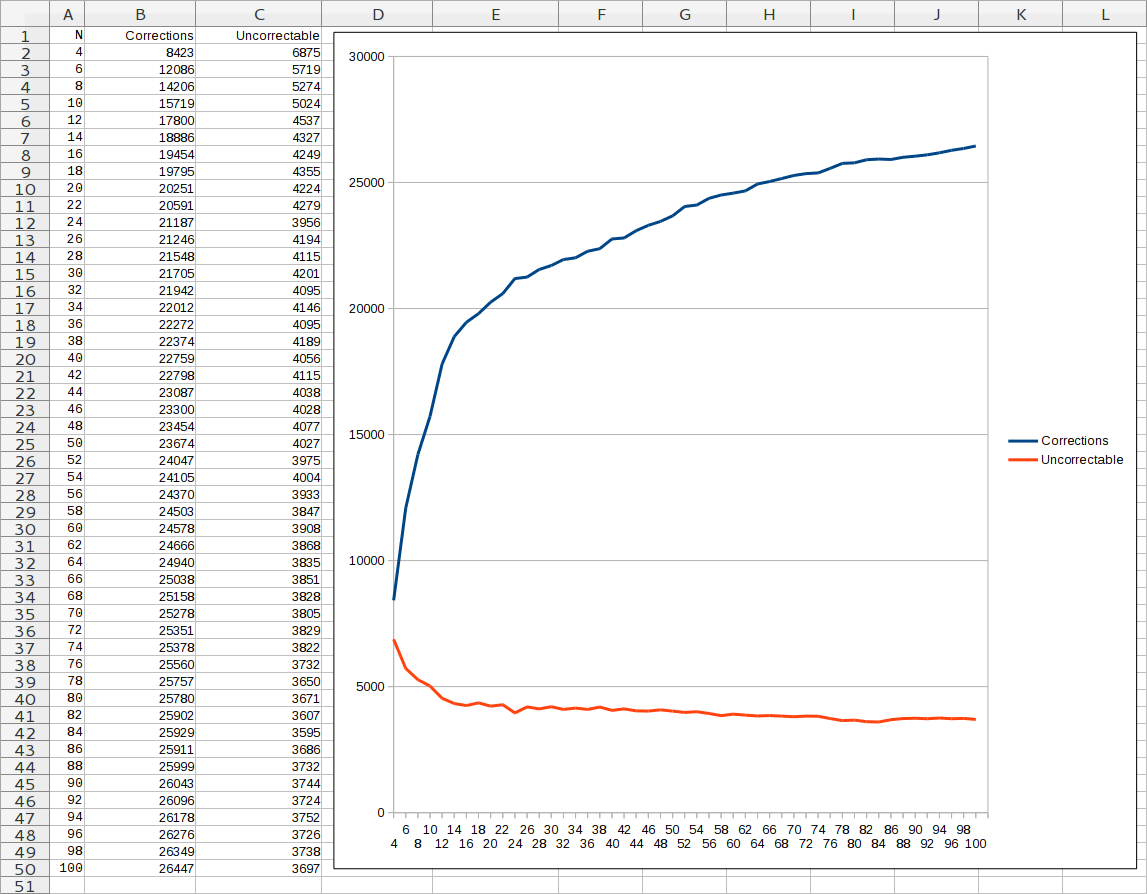
Corrected and uncorrectable errors per rip count
I started by ripping one of the CDs repeatedly, recording all the values for each byte, and declaring an error "correctable" if more than half of the rips had used a particular byte value at that position. Initial behavior was good, the number of uncorrectable errors dropped from almost ~6900 bytes at N=4 to ~5000 bytes at N=10. The per-rip benefit slowly decreased over time, until at around N=80 the uncorrectable error count stabilized at ~3700. I stopped ripping at N=100.
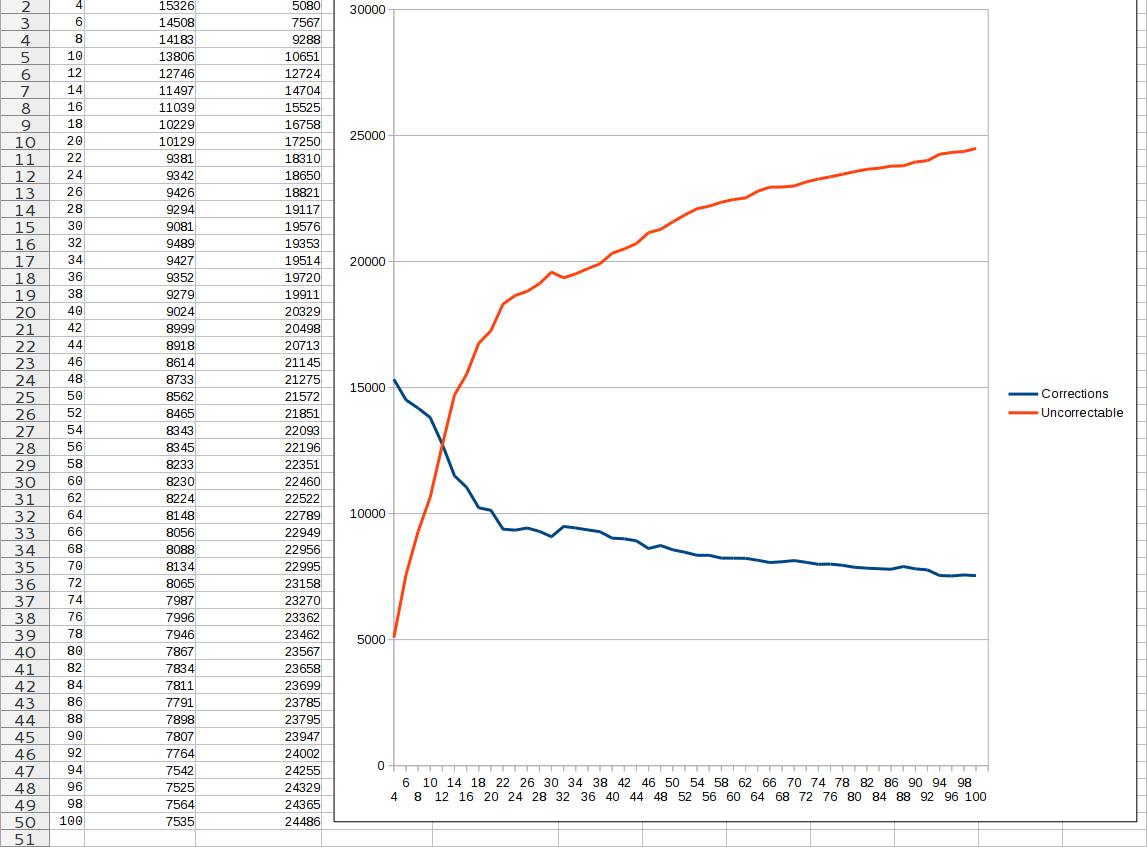
Same, but for two disks with cross-checked corrections
Next I tried ripping the second CD 100 times and using the two correction maps to "fill in" uncorrectable error positions in the other disk. This was a failure: each disk had thousands of corrections that disagreed with corrections on the other disk! It turns out you can't fix noisy data by intersecting it with a different-but-related noise source.
Arts and Crafts

The EAC site has another nice resource: the DAE Quality Test, which quantifies the error correction capability of an optical disk drive's firmware. This is a different, lower-level type of error handling that can fix read errors instead of merely reporting them. The catch is that EAC's "secure mode" works by disabling or avoiding this built-in correction code, on the assumption that it doesn't work well.
The test is prepared by burning a provided waveform to a CD-R, cutting some divots in the data surface, then carefully coloring part of it with black marker. That's it – guaranteed unrecoverable errors in a deterministic pattern.
I ran the test on all of the drives, obtaining two interesting results:
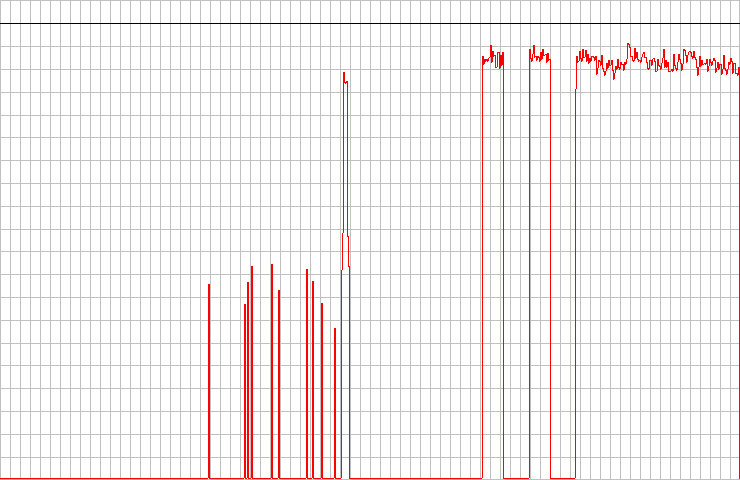
The Lite-On drive here is what I used to get past the sync error. It happily chews through the magic marker, but gets really confused by straight lines cut in the data surface. You can see how what should be three distinct peaks on the right get merged into one giant error blob.
Errors total Num : 206645159 Errors (Loudness) Num : 965075 - Avg : -21.7 dB(A) - Max : -5.5 dB(A) Error Muting Num : 154153 - Avg : 99.1 Samples - Max : 3584 Samples Skips Num : 103 - Avg : 417.3 Samples - Max : 2939 Samples Total Test Result : 45.3 points (of 100.0 maximum)
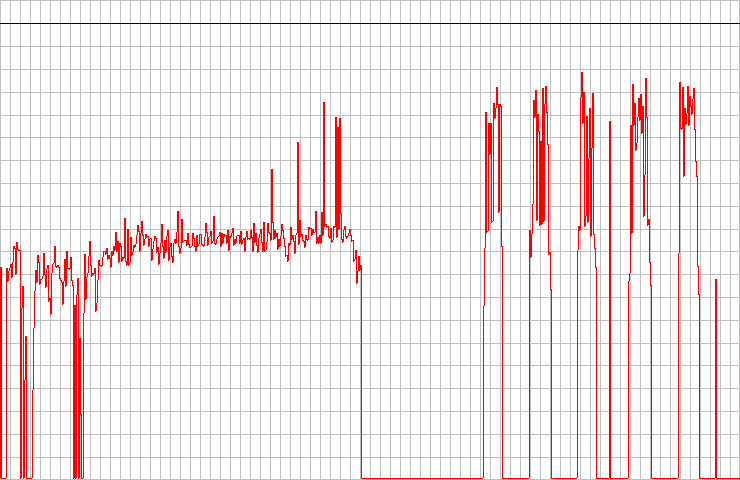
The Pioneer drive scored the highest on the DAE test. To my eye the chart doesn't look like anything special, but the analysis tool judged it the best error-correction firmware in my little fleet.
Errors total Num : 2331952 Errors (Loudness) Num : 147286 - Avg : -77.2 dB(A) - Max : -13.2 dB(A) Error Muting Num : 8468 - Avg : 1.5 Samples - Max : 273 Samples Skips Num : 50 - Avg : 6.5 Samples - Max : 30 Samples Total Test Result : 62.7 points (of 100.0 maximum)
“At some point numbers do count”
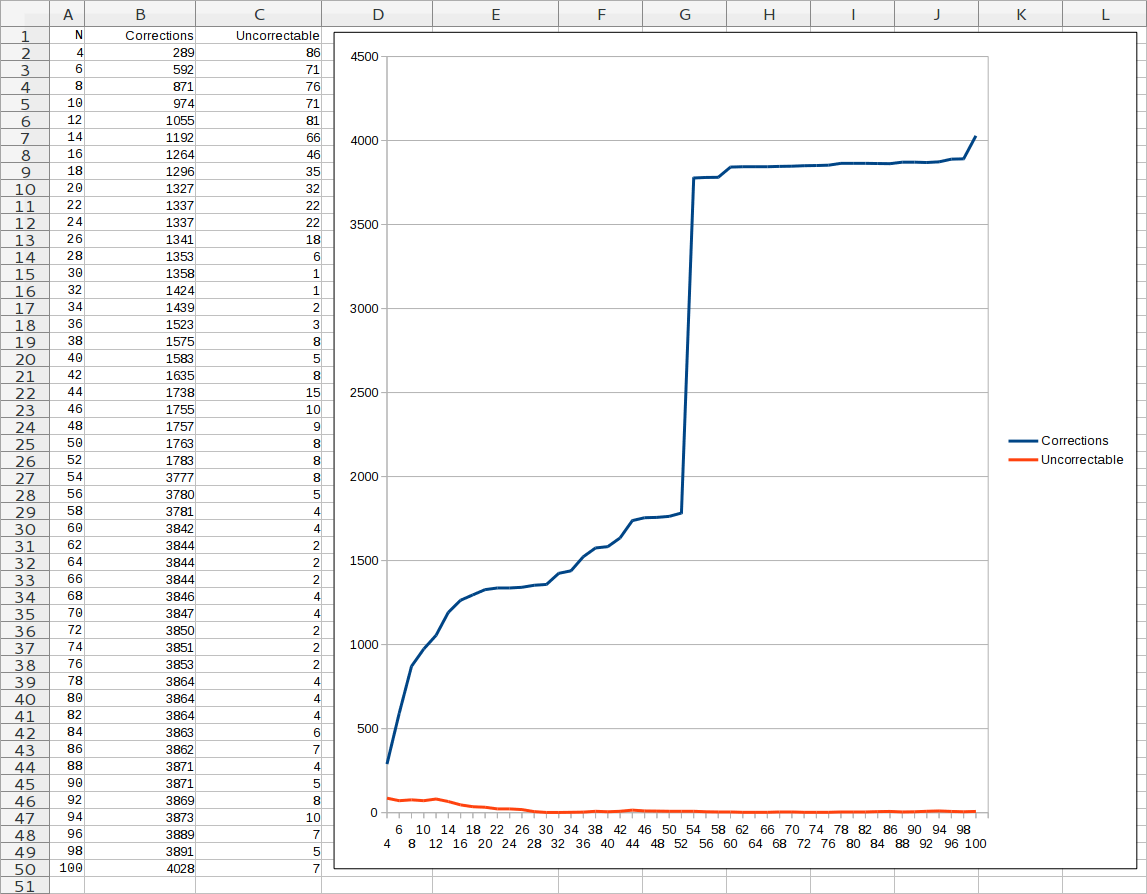
Corrected and uncorrectable errors per rip count (Pioneer)
How can I use the Pioneer's good innate error handing when EAC's "secure mode" works by bypassing a drive's error logic? That's easy, switch EAC to "burst mode" and let it write the bits to disk just as the firmware reported them. How can we turn that heap of unchecked wavs into a file of "secure mode" quality? The same error analysis tooling built for the Lite-On rips!
A few EAC config tweaks and another hundred rips later, we get this beautiful chart. A few things to note:
- The uncorrectable bit errors quickly approach zero, but never quite get there.
- There's a huge jump in corrected errors in the 53rd or 54th rip.
- The error counts before and after that big jump have some flat areas, indicating areas of stability in the ripped data.
0xA595BC09
Using the nearly-perfect correction data from the Pioneer, I generated a "best guess" file and started comparing it to the Pioneer rips. As expected there were some bad outliers, which I fixed by ripping ten more times:
for RIP_ID in $(seq -w 1 100); do echo -n "rip$RIP_ID: "; cmp -l analysis-out.wav rips-cd1-pioneer/rip${RIP_ID}/*.wav | wc -l ; done | sort -rgk2 | head -n 10
# rip054: 2865
# rip099: 974
# rip007: 533
# rip037: 452
# rip042: 438
# rip035: 404
# rip006: 392
# rip059: 381
# rip043: 327
# rip014: 323
I also found something really interesting, a handful of rips had come out with exactly the same audio content! Remember that this is what the EAC "secure mode" is designed to test for as a success criteria. That shncat -q -e | rhash --print="%C" snippet is used to calculate the CRC32 checksum of the raw audio data, and it's what EAC uses.
for wav in rips-cd1-pioneer/*/*.wav; do shncat "$wav" -q -e | rhash --printf="%C $wav\n" - ; done | sort -k1 # [...] # 9DD05FFF rips-cd1-pioneer/rip059/rip.wav # 9F8D1B53 rips-cd1-pioneer/rip072/rip.wav # A2EA0283 rips-cd1-pioneer/rip082/rip.wav # A595BC09 rips-cd1-pioneer/rip021/rip.wav # A595BC09 rips-cd1-pioneer/rip022/rip.wav # A595BC09 rips-cd1-pioneer/rip023/rip.wav # A595BC09 rips-cd1-pioneer/rip024/rip.wav # A595BC09 rips-cd1-pioneer/rip025/rip.wav # A595BC09 rips-cd1-pioneer/rip026/rip.wav # A595BC09 rips-cd1-pioneer/rip027/rip.wav # A595BC09 rips-cd1-pioneer/rip028/rip.wav # A595BC09 rips-cd1-pioneer/rip030/rip.wav # A595BC09 rips-cd1-pioneer/rip031/rip.wav # A595BC09 rips-cd1-pioneer/rip040/rip.wav # A595BC09 rips-cd1-pioneer/rip055/rip.wav # A595BC09 rips-cd1-pioneer/rip058/rip.wav # AA3B5929 rips-cd1-pioneer/rip043/rip.wav # ABAAE784 rips-cd1-pioneer/rip033/rip.wav # [...]
Setting that aside for now, re-ripping the outliers let the analysis complete with zero uncorrectable errors. And when I checked that file, it had the same audio content as the "common" rip!
I am 99% confident that I have correctly digitised this troublesome CD, with 0xA595BC09 being the correct CRC of track #3.
UPDATE: A Perfect Rip
After a Hacker News comment pointed me in the right direction (see Error Beneath the WAVs), I bought another CD drive (this one's drive #6) that was reported to have better handling of this particular problem. It was able to successfully rip the original disc with no issues.
At last, victory!
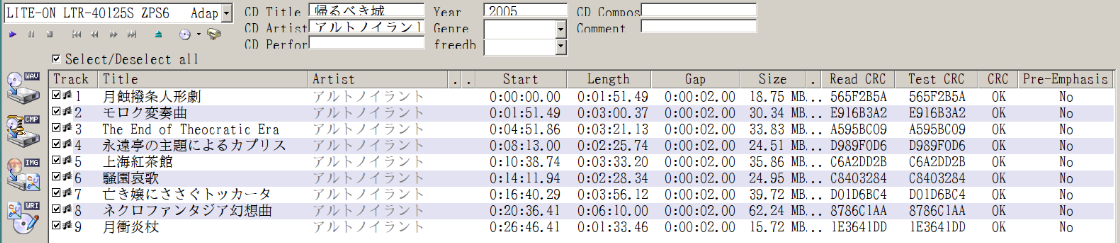
Track 3
Filename C:\Archive\アルトノイラント - 帰るべき城 [ANL-001]\03 - The End of Theocratic Era.wav
Pre-gap length 0:00:02.00
Peak level 100.0 %
Extraction speed 8.2 X
Track quality 100.0 %
Test CRC A595BC09
Copy CRC A595BC09
Accurately ripped (confidence 1) [84B9DD1A] (AR v2)
Copy OK
Appendix A: compare.rs
This is the tool I used to calculate suspected byte errors. It wasn't intended to live long so it's a bit ugly, but may be of interest to anyone who stumbles across this page with the same goal.
extern crate memmap;
use std::cmp;
use std::collections::HashMap;
use std::env;
use std::fs;
use std::sync;
use std::sync::mpsc;
use std::thread;
use memmap::Mmap;
const CHUNK_SIZE: usize = 1 << 20;
fn suspect_positions(
mmaps: &HashMap<String, Mmap>,
start_idx: usize,
end_idx: usize,
) -> Vec<usize> {
let mut positions = Vec::new();
for ii in start_idx..end_idx {
let mut first = true;
let mut byte: u8 = 0;
for (_file_name, file_content) in mmaps {
if first {
byte = file_content[ii];
first = false;
}
else if byte != file_content[ii] {
positions.push(ii);
break;
}
}
}
positions
}
fn main() {
let mut args: Vec<String> = env::args().collect();
args.remove(0);
let mut first = true;
let mut size: usize = 0;
let mut files: Vec<fs::File> = Vec::new();
let mut mmaps: HashMap<String, Mmap> = HashMap::new();
for filename in args {
let mut file = fs::File::open(&filename).unwrap();
files.push(file);
let mmap = unsafe { Mmap::map(files.last().unwrap()).unwrap() };
if first {
first = false;
size = mmap.len();
} else {
assert!(size == mmap.len());
}
mmaps.insert(filename, mmap);
}
let (suspects_tx, suspects_rx) = mpsc::channel();
let mut start_idx = 0;
let mmaps_ref = sync::Arc::new(mmaps);
loop {
let t_start_idx = start_idx;
let t_end_idx = cmp::min(start_idx + CHUNK_SIZE, size);
if start_idx == t_end_idx {
break;
}
let mmaps_ref = mmaps_ref.clone();
let suspects_tx = suspects_tx.clone();
thread::spawn(move || {
let suspects = suspect_positions(mmaps_ref.as_ref(), t_start_idx, t_end_idx);
suspects_tx.send(suspects).unwrap();
});
start_idx = t_end_idx;
}
drop(suspects_tx);
let mut suspects: Vec<usize> = Vec::with_capacity(size);
for mut suspects_chunk in suspects_rx {
suspects.append(&mut suspects_chunk);
}
suspects.sort();
println!("{{\"files\": [");
let mut first_file = true;
for (file_name, file_content) in mmaps_ref.iter() {
let file_comma = if first_file { "" } else { "," };
first_file = false;
println!("{}{{\"name\": \"{}\", \"suspect_bytes\": [", file_comma, file_name);
for (ii, position) in suspects.iter().enumerate() {
let comma = if ii == suspects.len() - 1 { "" } else { "," };
println!("[{}, {}]{}", position, file_content[*position], comma);
}
println!("]}}");
}
println!("]}}");
}
I've had a couple people ask "what's so special about track #3 that you would go through this?". Funny thing – track #3 was the only non-piano track on this album, and I actually don't like it very much! I will probably not listen to it often, or ever! This effort was not about the music itself, but about making a perfect copy of an ephemeral physical artifact.
That single AccurateRip entry for this album matched my CRCs for all tracks except track #3 – they had 0x84B9DD1A, vs my result of 0xA595BC09. I suspect that original ripper didn't realize their disk was bad.- My original footnote here was wrong. The AccurateRip report is correct (and matches my result) – I didn't realize AccurateRip uses a different checksum than EAC. The perfect rip reports an AccurateRip match on all tracks.
The obvious question when buying a CD- or DVD-ROM drive, here in the year in 2018, is "lol where?". And I didn't want just one, I wanted several, from different brands. There is only one bricks-and-mortar store I know of that would have an inventory of 5.25" DVD drives. Only one that's big enough to spare the shelf space but crufty enough that they wouldn't be out of place. I speak, of course, of Frys Electronics.